Using NodeRed to publish data to Azure Table Storage

In my HomeAutomation project, I'm using NodeRed and ioBroker as an On-Premise Workflow engine. But for reporting, I wanted to have some data in Azure Table Storage...
As none of the existing NodeRed Nodes where able to fulfill my needs, I've implemented my own Workflow with nothing else than the "http request" node..
As I have three different data-sources, the full workflow does look like this:
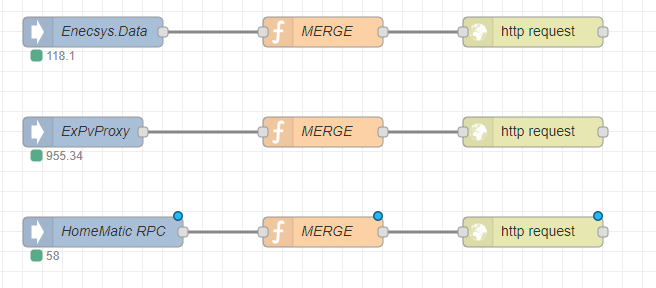
The first node does listen to some specific ioBroker events. The second Node will prepare the input to make a HTTP Merge request and the third node will send the request to the cloud.
In detail, the "MERGE" function is a simple script to prepare Headers, URL etc.:
var URL = "https://{StorageAccountName}.table.core.windows.net"
var Table = "{TableName}"
var SASToken = "{paste your SAS-Token here}"
var PartitionKey = "{aUniqueKey}"
var Device = msg.topic.split('/')[2] + ":" + msg.topic.split('/')[3]
var Attrib = msg.topic.split('/')[4]
var body = { PartitionKey: PartitionKey ,RowKey: Device , [Attrib] : msg.payload}
msg.payload = body
msg.headers = {};
msg.headers['x-ms-version'] = '2017-04-17';
msg.headers['Content-Type'] = 'application/json';
msg.headers['Accept'] = 'application/json;odata=fullmetadata';
msg.url = URL + "/" + Table + "(PartitionKey='" + PartitionKey + "',RowKey='" + Device+ "')" + SASToken
msg.method = 'merge'
return msg;
- Device: unique device identifier. In my case: one row per device
- Attrib: Name of the column to store the data value
- body: JSON body including PartitionKey,RowKey and Attribute Name and Value to merge
Note: The benefit of using a Merge is that it will create the row if the RowKey does not exists.
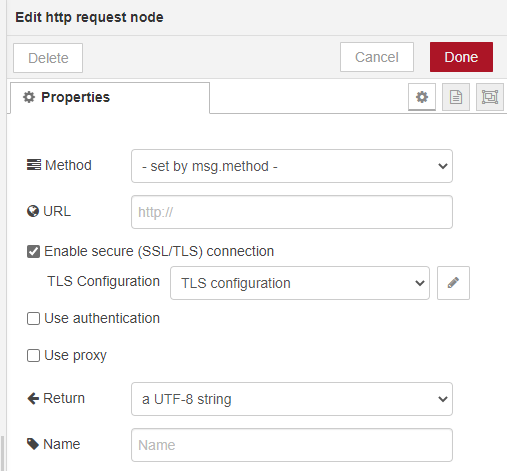
The "http request" node must be configured to get the Method from the msg.method property:
That's all you need to publish some data to Azure Table Storage...